Examiner les changements de contenu de données
Introduction
Les tables de log et la table interne des états des séquences constituent une mine d’or pour qui veut analyser les changements de données intervenus entre deux marques. Au delà de l’annulation et du comptage des changements déjà présentés, il est aussi possible de visualiser ces changements sous différentes formes.
Tout d’abord, tout utilisateur disposant des droits emaj_adm ou emaj_viewer peut consulter directement les tables de log. Leur structure est décrite ici.
Mais deux fonctions, emaj_dump_changes_group() et emaj_gen_sql_dump_changes_group(), peuvent faciliter cet examen. Elles permettent de visualiser les changements de contenu de données, pour chaque table et séquence d’un groupe de tables, et sur un intervalle de temps borné par deux marques.
Types de sortie
Pour répondre à de nombreux cas d’usage, la visualisation des changements de contenu de données peut prendre différentes formes :
un jeu de fichiers plats créés par des requêtes COPY TO (donc dans l’espace disque de l’instance PostgreSQL) ;
un script psql permettant d’obtenir des fichiers plats par des commandes \copy to (donc dans l’espace disque du client) ;
une table temporaire contenant des requêtes SQL permettant à un client quelconque de directement visualiser et exploiter les changements de données.
Niveaux de consolidation
Différents niveaux de visualisation des changements sont proposés au travers du concept de consolidation.
Sans consolidation, chaque changement élémentaire enregistré dans les tables de log est restitué. On obtient donc de simples extraits de tables de log pour la tranche de temps ciblée.
Le processus de consolidation vise à ne présenter que l’état initial (à la marque de début) et/ou l’état final (à la marque de fin) de chacune des clés primaires pour lesquelles des changements ont été enregistrés. Pour chaque clé primaire, on obtiendra une ligne de type “OLD”, représentant l’état initial si la clé existe déjà, et/ou une ligne de type “NEW” représentant l’état final si la clé existe toujours. La consolidation nécessite donc la présence de PRIMARY KEY sur toutes les tables examinées.
Deux niveaux de consolidation sont possibles :
la consolidation partielle ne tient pas compte du contenu effectif des changements,
la consolidation totale considère comme un non changement des contenus de données strictement identiques entre les deux marques.
Prenons quelques exemples, avec une simple table de 2 colonnes (col1 INT PRIMARY KEY, col2 CHAR) :
SQL entre les 2 marques |
Table de log (*) |
Consolidation partielle |
Consolidation totale |
|---|---|---|---|
INSERT (1,’A’)
|
1,’A’,NEW,1
|
1,’A’,NEW
|
1,’A’,NEW
|
UPDATE (1,’A’) => (1,’B’)
|
1,’A’,OLD,1
1,’B’,NEW,1
|
1,’A’,OLD
1,’B’,NEW
|
1,’A’,OLD
1,’B’,NEW
|
DELETE (1,’A’)
|
1,’A’,OLD,1
|
1,’A’,OLD
|
1,’A’,OLD
|
INSERT (1,’A’)
UPDATE (1,’A’) => (1,’B’)
|
1,’A’,NEW,1
1,’A’,OLD,2
1,’B’,NEW,2
|
1,’B’,NEW
|
1,’B’,NEW
|
UPDATE (1,’A’) => (1,’B’)
DELETE (1,’B’)
|
1,’A’,OLD,1
1,’B’,NEW,1
1,’B’,OLD,1
|
1,’A’,OLD
|
1,’A’,OLD
|
UPDATE (1,’A’) => (1,’B’)
UPDATE (1,’B’) => (1,’C’)
UPDATE (1,’C’) => (1,’D’)
|
1,’A’,OLD,1
1,’B’,NEW,1
1,’B’,OLD,2
1,’C’,NEW,2
1,’C’,OLD,3
1,’D’,NEW,3
|
1,’A’,OLD
1,’D’,NEW
|
1,’A’,OLD
1,’D’,NEW
|
INSERT (1,’A’)
DELETE (1,’A’)
|
1,’A’,NEW,1
1,’A’,OLD,2
|
-
|
-
|
DELETE (1,’A’)
INSERT (1,’B’)
|
1,’A’,OLD,1
1,’B’,NEW,2
|
1,’A’,OLD
1,’B’,NEW
|
1,’A’,OLD
1,’B’,NEW
|
UPDATE (1,’A’) => (1,’B’)
UPDATE (1,’B’) => (1,’A’)
|
1,’A’,OLD,1
1,’B’,NEW,1
1,’B’,OLD,2
1,’A’,NEW,2
|
1,’A’,OLD
1,’A’,NEW
|
-
|
DELETE (1,’A’)
INSERT (1,’A’)
|
1,’A’,OLD,1
1,’A’,NEW,2
|
1,’A’,OLD
1,’A’,NEW
|
-
|
UPDATE (1,’A’) => (2,’A’)
UPDATE (2,’A’) => (2,’B’)
UPDATE (2,’B’) => (3,’B’)
|
1,’A’,OLD,1
2,’A’,NEW,1
2,’A’,OLD,2
2,’B’,NEW,2
2,’B’,OLD,3
3,’B’,NEW,3
|
1,’A’,OLD,1
3,’B’,NEW
|
1,’A’,OLD
3,’B’,NEW
|
(*) l’extrait de la table de log correspond aux colonnes (col1, col2, emaj_tuple, emaj_gid), les autres colonnes techniques E-Maj n’étant pas mentionnées.
Prudence
Quelques rares types de données, tels que les JSON ou XML, ne disposent pas d’opérateur d’égalité. Dans ce cas, la consolidation de type complète opère un transtypage de la donnée en TEXT pour la comparaison entre les valeurs initiale et finale.
Pour chaque séquence, deux lignes sont restituées, correspondant à l’état initial et l’état final de la séquence. Dans une visualisation de type consolidation totale, aucune ligne n’est restituée si ces deux états sont strictement identiques.
Vidage des mises à jour sur fichiers
La fonction emaj_dump_changes_group() extrait les changements des tables de log et de la table des états des séquences et crée des fichiers dans l’espace disque de l’instance PostgreSQL, au moyen de requêtes COPY TO :
SELECT emaj.emaj_dump_changes_group(p_group, p_firstMark, p_lastMark,
p_optionsList, p_tblseqs, p_dir);
Paramètres en entrée
p_group(TEXT) : Nom du groupe de tables.p_firstMark(TEXT) : Nom de la marque représentant le début de la période.p_lastMark(TEXT) : Nom de la marque représentant le fin de la période. Le mot cléEMAJ_LAST_MARKreprésente la dernière marque posée.p_optionsList(TEXT) : Liste d’options.p_tblseqs(TEXT[]) : Tableau des tables et sequences à traiter. NULL signifie que toutes les tables et séquences du groupe sont traitées.p_dir(TEXT) : Répertoire de sortie.
Données retournées
La fonction retourne un message textuel contenant le nombre de fichiers générés et leur localisation.
Notes
Durant l’extraction, le groupe de tables peut être actif ou non.
Si l’intervalle de marques n’est pas contenu dans une seule session de log, c’est à dire si des arrêts/relances du groupe de tables ont eu lieu entre ces deux marques, un message d’avertissement est retourné, indiquant que des mises à jour de données ont pu ne pas être enregistrées.
Le paramètre p_optionsList est une liste d’options, séparées par des virgules. Les options peuvent prendre les valeurs suivantes (par ordre alphabétique) :
COLS_ORDER = LOG_TABLE | PK : définit l’ordre des colonnes dans les fichiers de sortie (LOG_TABLE = le même ordre que dans les tables de log, PK = les colonnes de clé primaire en tête) ;
CONSOLIDATION = NONE | PARTIAL | FULL : définit le niveau de consolidation souhaité ; la valeur par défaut est NONE ;
COPY_OPTIONS = (options) : définit les options à utiliser par les requêtes COPY TO ; la liste doit être placée entre parenthèses ; voir la documentation de PostgreSQL pour le détail des options disponibles (https://www.postgresql.org/docs/current/sql-copy.html) ;
EMAJ_COLUMNS = ALL | MIN | (liste.colonnes) : restreint la liste des colonnes techniques E-Maj restituées : ALL = toutes les colonnes techniques existantes, MIN = un nombre minimum de colonnes, ou une liste explicite de colonnes placée entre parenthèses ;
NO_EMPTY_FILES : supprime les éventuels fichiers sans donnée ;
ORDER_BY = PK | TIME : définit le critère de tri des lignes dans les fichiers ; PK = l’ordre des clés primaires, TIME = l’ordre d’entrée dans la table de log ;
SEQUENCES_ONLY : ne traite que les séquences du groupe de tables ; par défaut, les tables sont traitées ;
TABLES_ONLY : ne traite que les tables du groupe de tables ; par défaut les séquences sont traitées.
La valeur par défaut des trois options COLS_ORDER, EMAJ_COLUMNS et ORDER_BY dépend du niveau de consolidation :
quand CONSOLIDATION = NONE, COLS_ORDER = LOG_TABLE, EMAJ_COLUMNS = ALL et ORDER_BY = TIME ;
quand CONSOLIDATION = PARTIAL ou FULL, COLS_ORDER = PK, EMAJ_COLUMNS = MIN et ORDER_BY = PK.
Le paramètre p_tblseqs permet de sélectionner les tables et séquences à traiter. Si le paramètre a la valeur NULL, toutes les tables et séquences du groupe de tables sont traitées. S’il est spécifié, le paramètre doit être exprimé sous la forme d’un tableau non vide d’éléments de type texte, chacun d’eux représentant le nom d’une table ou d’une séquence préfixé par son nom de schéma. On peut utiliser indifféremment les syntaxes :
ARRAY['sch1.tbl1','sch1.tbl2']
ou :
'{ "sch1.tbl1" , "sch1.tbl2" }'
Les effets de ce paramètre p_tblseqs et des options SEQUENCES_ONLY et TABLES_ONLY sont cumulatifs. Par exemple, une séquence listée dans le tableau ne sera pas traitée si l’option TABLES_ONLY est positionnée.
Le paramètre p_dir est le répertoire de sortie. Il doit être exprimé en chemin absolu. Ce répertoire doit exister au préalable et avoir les permissions adéquates pour que l’instance PostgreSQL puisse y écrire.
Lorsque la structure du groupe de tables est stable entre les deux marques ciblées, la fonction emaj_dump_changes_group() génère un fichier par table et par séquence. Le nom des fichiers créés pour chaque table ou séquence est du type :
<nom.schema>_<nom.table.ou.séquence>.changes
Pour faciliter la manipulation des fichiers générés, d’éventuels caractères espaces, « / », « \ », « $ », « > », « < », “|”, simples ou doubles guillemets et « * » sont remplacés par des « _ ». Attention, cette adaptation des noms de fichier peut conduire à des doublons, le dernier fichier généré écrasant alors les précédents.
Tous ces fichiers sont stockés dans le répertoire ou dossier correspondant au paramètre p_dir. D’éventuels fichiers de même nom déjà présents dans le répertoire sont écrasés.
En fin d’opération, un fichier _INFO est créé dans ce même répertoire. Il contient :
les caractéristiques de l’opération effectuée : le groupe de tables, les marques et options sélectionnées, et la date et heure de l’opération ;
une ligne par fichier créé indiquant la table/séquence concernée et la tranche de marques associée.
Comme la fonction peut générer de gros, voire très gros, fichiers, il est de la responsabilité de l’utilisateur de prévoir un espace disque suffisant.
Générer du SQL de vidage des mises à jour
La fonction emaj_gen_sql_dump_changes_group() génère des requêtes SQL permettant d’extraire les changements des tables de log et de la table des états des séquences :
SELECT emaj.emaj_gen_sql_dump_changes_group(p_group, p_firstMark, p_lastMark,
p_optionsList, p_tblseqs, p_scriptLocation);
Paramètres en entrée
p_group(TEXT) : Nom du groupe de tables.p_firstMark(TEXT) : Nom de la marque représentant le début de la période.p_lastMark(TEXT) : Nom de la marque représentant le fin de la période. Le mot cléEMAJ_LAST_MARKreprésente la dernière marque posée.p_optionsList(TEXT) : Liste d’options.p_tblseqs(TEXT[]) : Tableau des tables et sequences à traiter. NULL signifie que toutes les tables et séquences du groupe sont traitées.p_scriptLocation(TEXT, optionnel) : Localisation du fichier de sortie. Si NULL, les requêtes sont générées dans une table temporaire.
Données retournées
La fonction retourne un message textuel contenant le nombre de requêtes générées et leur localisation.
Notes
Durant la génération, le groupe de tables peut être actif ou non.
Si l’intervalle de marques n’est pas contenu dans une seule session de log, c’est à dire si des arrêts/relances du groupe de tables ont eu lieu entre ces deux marques, un message d’avertissement est retourné, indiquant que des mises à jour de données ont pu ne pas être enregistrées.
Le paramètre p_optionsList est une liste d’options, séparées par des virgules. Les options peuvent prendre les valeurs suivantes (par ordre alphabétique) :
COLS_ORDER = LOG_TABLE | PK : définit l’ordre des colonnes dans les fichiers de sortie (LOG_TABLE = le même ordre que dans les tables de log, PK = les colonnes de clé primaire en tête) ;
CONSOLIDATION = NONE | PARTIAL | FULL : définit le niveau de consolidation souhaité ; la valeur par défaut est NONE ;
EMAJ_COLUMNS = ALL | MIN | (columns list) : restreint la liste des colonnes techniques E-Maj : ALL = toutes les colonnes techniques existantes, MIN = un nombre minimum de colonnes, ou une liste explicite de colonnes placée entre parenthèses ;
ORDER_BY = PK | TIME : définit le critère de tri des lignes dans les fichiers ; PK = l’ordre des clés primaires, TIME = l’ordre d’entrée dans la table de log ;
PSQL_COPY_DIR = (répertoire) : génère une méta-commande psql \copy pour chaque requête, en utilisant le nom du répertoire fourni par l’option ; le nom du répertoire doit être placé entre parenthèses ;
PSQL_COPY_OPTIONS = (options) : quand l’option PSQL_COPY_DIR est valorisée, définit les options à utiliser par les méta-commande psql \copy ; la liste doit être placée entre parenthèses ; voir la documentation de PostgreSQL pour le détail des options disponibles (https://www.postgresql.org/docs/current/sql-copy.html) ;
SEQUENCES_ONLY : ne traite que les séquences du groupe de tables ; par défaut, les tables sont traitées ;
SQL_FORMAT = RAW | PRETTY : définit la façon dont les requêtes générées sont formatées : RAW = sur une seule ligne, PRETTY = sur plusieurs lignes avec indentation pour une lecture plus aisée ;
TABLES_ONLY : ne traite que les tables du groupe de tables ; par défaut les séquences sont traitées.
Pour les trois options COLS_ORDER, EMAJ_COLUMNS et ORDER_BY, la valeur par défaut dépend du niveau de consolidation :
quand CONSOLIDATION = NONE, COLS_ORDER = LOG_TABLE, EMAJ_COLUMNS = ALL et ORDER_BY = TIME ;
quand CONSOLIDATION = PARTIAL ou FULL, COLS_ORDER = PK, EMAJ_COLUMNS = MIN et ORDER_BY = PK.
Le paramètre p_tblseqs permet de sélectionner les tables et séquences à traiter. Si le paramètre a la valeur NULL, toutes les tables et séquences du groupe de tables sont traitées. S’il est spécifié, le paramètre doit être exprimé sous la forme d’un tableau non vide d’éléments de type texte, chacun d’eux représentant le nom d’une table ou d’une séquence préfixé par son nom de schéma. On peut utiliser indifféremment les syntaxes :
ARRAY['sch1.tbl1','sch1.tbl2']
ou :
'{ "sch1.tbl1" , "sch1.tbl2" }'
Les effets de ce paramètre p_tblseqs et des options SEQUENCES_ONLY et TABLES_ONLY sont cumulatifs. Par exemple, une séquence listée dans le tableau ne sera pas traitée si l’option TABLES_ONLY est positionnée.
Le paramètre p_scriptLocation est facultatif. S’il est absent, les requêtes générées sont mises à la disposition de l’appelant dans une table temporaire, emaj_temp_sql. S’il est présent, les requêtes sont écrites dans le fichier défini par le paramètre. Le nom de fichier doit alors être un chemin absolu. Le répertoire doit exister au préalable et avoir les permissions adéquates pour que l’instance PostgreSQL puisse y écrire.
Si des noms de schémas, de tables ou de colonnes contiennent des caractères « \ » (antislash), la commande COPY qui crée le fichier script double ces caractères. Si une commande sed est disponible sur le serveur hébergeant l’instance PostgreSQL, la fonction emaj_gen_sql_dump_changes_group() dédouble automatiquement ces caractères « \ ». Sinon, il est nécessaire de retraiter manuellement le script généré.
La table temporaire emaj_temp_sql, mise à la disposition de l’appelant quand le dernier paramètre est absent, a la structure suivante :
sql_stmt_number (INT) : numéro de la requête
sql_line_number (INT) : numéro de ligne de la requête (0 pour les commentaires, 1 pour une requête complète quand SQL_FORMAT = RAW, 1 à n quand SQL_FORMAT = PRETTY)
sql_rel_kind (TEXT) : type de relation (« table » ou « sequence »)
sql_schema (TEXT) : schéma contenant la table ou séquence applicative
sql_tblseq (TEXT) : nom de la table ou séquence
sql_first_mark (TEXT) : nom de la marque début pour cette table ou séquence
sql_last_mark (TEXT) : nom de la marque de fin pour cette table ou séquence
sql_group (TEXT) : nom du groupe de tables d’appartenance
sql_nb_changes (BIGINT) : nombre estimé de changements à traiter (NULL pour les séquences)
sql_file_name_suffix (TEXT) : suffixe du nom de fichier à générer quand l’option PSQL_COPY_DIR a été valorisée
sql_text (TEXT) : ligne de texte de la requête générée
sql_result (BIGINT) : colonne destinée à l’appelant pour son propre usage dans l’exploitation de la table temporaire.
La table contient :
une première requête de commentaire général, reprenant les caractéristiques de la génération : groupe de tables, marques, options, etc (sql_stmt_number = 0) ;
en cas de consolidation complète, une requête modifiant la variable de configuration enable_nestloop ; cette requête est nécessaire pour optimiser les analyses des tables de log, (sql_stmt_number = 1) ;
puis, pour chaque table et séquence traitée :
un commentaire propre à la table ou la séquence (sql_line_number = 0) ;
la requête d’analyse, sur une ou plusieurs lignes, en fonction de la valeur de l’option SQL_FORMAT ;
en cas de consolidation complète, une dernière requête repositionnant la variable enable_nestloop à sa valeur précédente.
Un index est créé sur les deux premières colonnes.
A l’issue de l’exécution de la fonction emaj_gen_sql_dump_changes_group(), l’appelant peut utiliser la table temporaire à sa guise. Avec des requêtes ALTER TABLE, il peut même ajouter une ou plusieurs autres colonnes, renommer la table, la transformer en table permanente. Il peut également créer un index supplémentaire si cela s’avère utile. Le nombre estimé de mises à jour peut être utile pour paralléliser efficacement l’exécution des requêtes.
L’appelant peut par exemple générer ensuite un script sql et le stocker localement avec une requête :
\copy (SELECT sql_text FROM emaj_temp_sql) to <fichier>
Il peut obtenir le SQL pour une table donnée avec : :
SELECT sql_text FROM emaj_temp_sql
WHERE sql_line_number >= 1
AND sql_schema = '<mon_schéma>' AND sql_tblseq = '<ma_table>';
La fonction emaj_gen_sql_dump_changes_group() peut être exécutée par un rôle disposant du droit emaj_viewer si aucun fichier n’est directement généré par la fonction.
Les impacts des changements de structure des groupes de tables
Il peut arriver que, sur l’intervalle de marques sélectionné, la structure du groupe de tables se trouve modifiée.
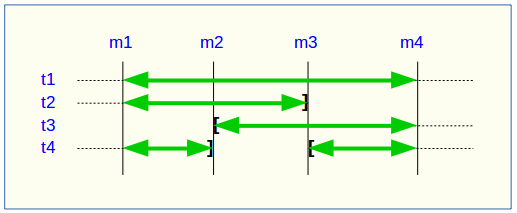
Une table ou une séquence peut être assignée au groupe ou retirée du groupe entre les marques début et fin sélectionnées, comme c’est le cas des tables t2 et t3 dans le graphique ci-desus. Les extractions portent alors sur les périodes réelles d’appartenance des tables et séquences à leur groupe de tables. C’est la raison pour laquelle le fichier _INFO ou la table emaj_temp_sql contiennent les informations relatives aux bornes effectivement utilisées pour chaque table ou séquence.
Une table ou séquence peut même être sortie de son groupe puis y être réintégrée ultérieurement, comme c’est le cas pour la table t4. Il y a alors plusieurs extractions pour la table ou séquence : la fonction emaj_gen_sql_dump_changes_group() génére plusieurs requêtes dans emaj_temp_sql et la fonction emaj_dump_changes_group() crée plusieurs fichiers pour la même table ou séquence. Le suffixe du nom de fichier produit devient alors _1.changes, _2.changes, etc.